3 The Experiment
In this section, we shall focus on key aspects of experimental design. We are also going to begin to look at the crucial connections between research design and statistics. Briefly, we shall look at the distinction between between- and within-subjects design; next we shall consider the various influences on the dependent variable.
Some influences we are interested in (the independent variable[s]), but others we really do not want (extraneous variables and confounds). So we shall discuss how to maximize the effect of the independent variable (IV) and minimize the effects of the extraneous variables and confounds. And then you will see why this is important—in particular how it relates to our statistical test.
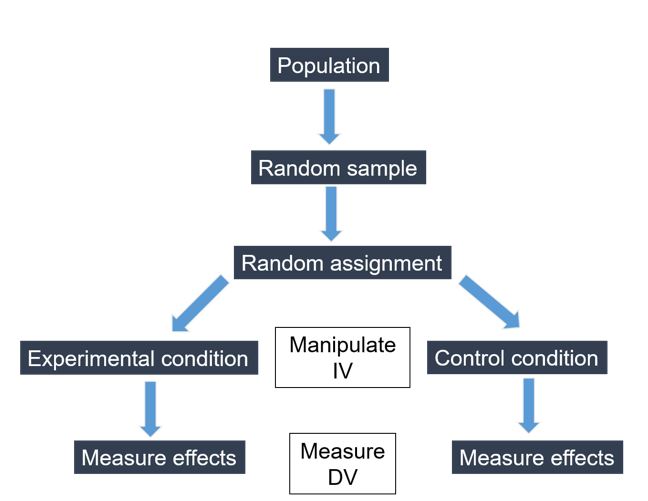
In the ideal experiment shown in Figure 1.3, we start by drawing a random sample from the population. We randomly assign our participants to an experimental condition or a control condition (note that in some experimental designs, there is no random assignment because participants complete both the experimental and the control conditions—more on that later).
With Max’s study of hair colour and perceived friendliness (see earlier in this chapter), Max would randomly assign participants to view either image A or image B. Each participant would rate the friendliness of the person viewed in the photo. In this case, we just have two levels of the independent variable (red hair = experimental condition, or brown hair = control condition), but Max could add further levels (e.g., blond hair, black hair, bald).
The Choice of Between- or Within-Subjects Experiment Design
We have two different ways to collect data in an experiment. In the between-groups (or between-subjects, independent) design, we have different people in the experimental conditions. In the example above, Max would randomly assign participants to view the photo of the person with red hair or the person with brown hair. One of the benefits of this approach is that it reduces demand characteristics compared to the within-subjects design.
Demand characteristics are when cues in the experiment inform the participant how the experimenter expects them to behave. As a result, participants may conform to those expectations. Demand characteristics can become a confound (i.e., they threaten internal validity because it looks like the independent variable influenced the dependent variable, but really the difference in scores between the conditions is due to demand characteristics).
Alternatively, we could use a within-subjects (or repeated measures design) where the same people take part in all conditions—in other words, participants would be exposed to all levels of the IV. The same participants would view both the image of the person with red hair and the image of the person with brown hair. There are various benefits to this approach, including that it can be more economical (it should require fewer participants because it controls for participant variables). However, it may lead to practice effects, fatigue (now the experiment is twice as long), and demand characteristics.
Later in the book, we shall look a bit more closely at how to choose between a between- and a within-subjects design.
Influences on the Dependent Variable
We have reviewed independent variables (IV) and dependent variables (DV). However, these are not the only variables at work in our experiment. Two other types of variables influence the dependent variable, so we need to pay close attention to them. The figure below is probably the most important (if the most mundane) figure in this whole book. Usually, when we think about experiments, we think about the very left part of the figure (systematic variation of the independent variable reflecting the experimental effect and causing observed differences in the dependent variable). However, it is critical to consider that both confounds and extraneous variables also cause differences in the dependent variable and will impact your ability to draw conclusions from your experiment, albeit in different ways.
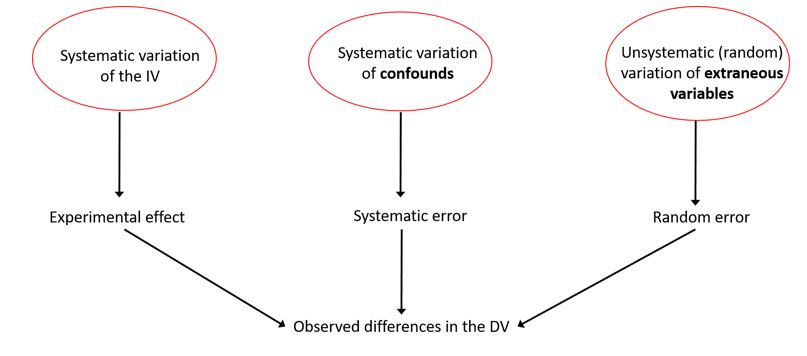
As you can see in Figure 1.4, there are three causes of variation in the scores on the dependent variable: systematic variation of the independent variable; systematic variation of confounds; and unsystematic variation of extraneous variables. We want systematic variation of the independent variable—this is what leads to our experimental effect. On the other hand, we do not want systematic variation of confounds or unsystematic variation of extraneous variables, both of which represent error.
So back to Max’s experiment, we would expect there to be some differences in friendliness scores due to Max’s experimental manipulation (the person in the photo has red hair or brown hair). These differences are due to systematic variation. We call this systematic because we deliberately and methodically manipulated the independent variable (hair colour). The variability in the dependent variable due to the manipulation of the independent variable are what we want to observe.
Extraneous Variables
The behaviour of participants is also influenced by unsystematic variation. By unsystematic, we mean that it is something we have not controlled or manipulated but that just happens to vary from one experimental condition to the next, or from one participant to the next. For example, imagine that one of Max’s participants was recently dumped in a most awful way (imagine the worst possible way to end a relationship) by a person with red hair. Based on that experience, that participant might not feel positively inclined towards people with red hair at the moment. Another participant might have a best friend with red hair and, therefore, thinks that people with red hair are the friendliest on the planet! So, the different participants in different conditions are going to vary in their general feelings towards people with red hair due to their idiosyncratic experiences, which is going to influence their perceptions of the friendliness of people in the photos with red or brown hair. Also, the mood that each participant is in when they take part in the experiment will influence how friendly they perceive the person in the photo to be (regardless of the hair colour). These variables (recent experiences with people with red hair, current mood) are going to contribute to random variation in the scores on the dependent variable.
We call these variables extraneous variables, because they were not manipulated, and they vary at random in the experiment. Extraneous variables can be characteristics of the participant (we call those participant variables, as in the examples above), or they could be characteristics of the experiment (e.g., time of day, experimenter characteristic, etc.). You can probably think of some other extraneous variables that might be at play here. The key thing to remember is that extraneous variables are (usually) unknown variables that we have not measured but that influence the dependent variable in some way. We do not really want them because, as we shall see later, they make it harder, statistically, for us to detect the experimental effect. Imagine the static on the radio when you are trying to pick up a signal: extraneous variables are like the static and the signal is your experimental effect.
Confounds
What can also be a problem is if these extraneous variables—unsystematic variation—start to vary in systematic ways. In other words, if they vary along with the independent variable. In that case, they can become confounds! A confound is a variable that varies systematically with (at the same time as) the independent variable.
So, for example, let’s say Max has two research assistants working with them. One research assistant is really friendly to the participants and is the researcher who happens to administer the experiment to all the participants who view the photo of the person with red hair. The other researcher is grumpy, and they administer the experiment to all the participants who view the photo with of the person with brown hair. Now the research assistant’s demeanour (friendly or grumpy) covaries with the manipulation of the independent variable (red hair or brown hair), so we would say that the research assistant’s demeanour is a confound. Why is this a problem? Well, if Max finds that the person with red hair was rated as more friendly than the person with brown hair, we do not know if that is due to the manipulation of the independent variable (red or brown hair colour) or the effect of the confound (research assistant’s friendly or grumpy demeanour). The confound has compromised internal validity.
The internal validity of our experiment refers to the extent to which the relationship between the independent variable and the dependent variable reflects only the relationship between them, and not effects due to other factors. Another way of saying this is to say that internal validity reflects the extent to which the apparent effect of the independent variable on the dependent variable is indeed due to our intended manipulation, and not due to the effect of confounding variables. We say that internal validity is good when we are confident that we have ruled out potential confounds.
What could be some other confounds in Max’s experiment? Let’s imagine that all the participants in the brown hair condition have to come into the lab for the experiment really early in the morning, but participants in the red hair condition come in later in the afternoon. Perhaps participants in the brown hair group perceive the person in the photo to be less friendly because they are tired and grumpy about coming in so early. Take a look back at the photos that Max used in the experiment (images A and B) earlier in this chapter. Do these give you a clue as to another potential confound?
In a nutshell:
| Type of variable | Do we want it? | Why or why not? |
| Independent variable | Yes | It is the effect of interest |
| Extraneous variable | No | Causes random variation in the dependent variable, making it harder to detect differences in groups/conditions that are due to the manipulation of the independent variable (i.e., reduce power – see chapter 4 on power) |
| Confounding variable | No | Compromises internal validity, meaning that we might think that the difference between groups/conditions is due to the manipulation of the independent variable, but really it is due to the confounding variable |
If you want further examples of confounding variables, see this great explanation by Karen Grace-Martin, “confusing statistical terms #11: confounder” from The Analysis Factor website.
So, what next? We need to maximize the effect of the independent variable and minimize the effects of extraneous variables and confounds. Next, we shall look at how to do each of these things in turn.
Maximizing the Effect of the Independent Variable
We can maximize the effect by having a strong manipulation. In other words, we select amounts of the independent variable that are substantially different from one another. Max should ensure that the red-haired person has really red hair and that the brown-haired person has clearly brown hair, with no hints of red. We also need to ensure that exposure is sufficient for the manipulation to influence behaviour: a 20 second display of the photo should be more effective than a 500 ms display.
There are of course caveats to having a strong manipulation. First we have to consider whether the manipulation is ecologically valid. Sometimes, a manipulation done in the lab would not be as strong in the real world. Second, it might be unethical to use a very strong manipulation (e.g., if I want to look at the effects of hunger on cognitive performance, it would not be ethical to starve my participants for five days before they complete a cognitive task). Finally, we should try to use a manipulation check. This is a measurement to determine if an intended manipulation of an independent variable actually occurred. Did each condition of the independent variable actually have its intended effect? Usually we assess this after participants have completed the dependent variable (note, the manipulation check is not the measurement of the dependent variable).
For example, imagine you are investigating if a cold room temperature influences attention when studying. Participants are randomly assigned to sit in a cold room or a warm room while they study a list of words, and later they are tested on their recall. The dependent variable is the number of words recalled. The manipulation check might entail asking participants in all conditions to rate how cold or warm they felt while studying the word list. If you only vary the temperature of the room by a little bit (e.g., warm room = 21 degrees; cold room = 20 degrees), the change might not be detectable to participants (manipulation check!) and may not be sufficient to influence their performance on the task (the effect on the dependent variable!). Then you might say that it was a weak manipulation.
Manipulation checks are particularly useful in a pilot study, which is when you are just beginning your research and testing out your measures. They can also be used at the end of an actual experiment to demonstrate that the manipulation of the independent variable did have the desired effect (again, note that this is not the same as the effect on the dependent variable). What are the advantages of using a manipulation check? If, in a pilot study, the manipulation did not work, we can save the expense of running the actual experiment. Alternatively, if we run our study and get non-significant results (no relationship between our independent variable and dependent variable), we can check whether this is due to a problem with the manipulation (for example, perhaps it was not strong enough).
Reducing the Influence of Confounds
To maximize internal validity, thereby reducing the possibility of confounds, the main goal is to keep everything as consistent as possible from one condition of the experiment to another except for the variable that is being manipulated (the independent variable). Thus, you need to think carefully about your research stimuli and other aspects of your study design. You may have noticed that Max had different people pose for the photos with red and brown hair. This is a design confound. It relates to an error in the experimental design. Max should have used the same person in each image presented to participants and used Photoshop to change the colour of the hair.
A summary of the many types of possible confounds is shown in the table below. You will sometimes see confounds described as “threats to internal validity,” because they are exactly that!
| Threat to internal validity | Definition |
| History effects | Non-manipulated external event occurs between two measurement timepoints |
| Maturation | Participants change over time and so produce different scores at two timepoints |
| Testing effect | Pretest sensitizes participants |
| Instrument decay | Characteristics of measurement instrument changes over time |
| Regression to the mean | Participants initially selected for extreme scores will be closer to mean on second measurement (statistical phenomenon) |
| Attrition | Participants with certain characteristics more likely to drop out of the study |
| Selection differences | Pre-existing differences in groups of participants |
| Demand characteristics | Subtle cues influences participants’ behaviour to respond in hypothesized direction |
| Design confound | Unintended characteristic of experiment covaries with IV |
| Order effects | Exposure to one level of IV changes response to other level of IV (e.g., practice, fatigue, carryover effects) |
| Placebo effect | Scores on DV change/improve because participants expect the IV to have an effect |
These above definitions are very brief, so you might want to look back at your notes from your introductory research methods class for a more detailed refresher. As you review these potential confounds: (a) for each one, consider whether it would be more likely to be an issue in a between-subjects design, a within-subjects design, or both; and (b) think of examples of what these might look like in Max’s hair colour and friendliness study (you might need to imagine both between- and within-subjects designs).
So, with these varied threats to internal validity in mind, how can we reduce them?
Using a between-subjects design will often reduce some threats to internal validity (e.g., maturation). Randomly assigning participants to groups is essential and will further eliminate some threats (e.g., selection differences). There is an important caveat about random assignment, however. Random assignment simply helps reduce the likelihood of there being systematic differences in extraneous variables between the two groups. Remember that randomization does not guarantee equivalent groups.
Demand characteristics are usually reduced in a between-subjects design. However, they may still be present. Thus, our comparison group ideally has a “placebo” of some kind. For example, if you want to test the effects of alcohol consumption on reading speed, participants in the placebo group would receive a drink that looks and tastes like the alcoholic drink, but without the critical ingredient (alcohol). At the very least, all participants should be blind to the condition they are in.
What if you are using a within-subjects design for other reasons (e.g., you may know that there are strong influence of participant variables on the dependent variable, so you wish to control for them by using a within-subjects design)? Then you will need to find ways to minimize practice effects, boredom or fatigue, and demand characteristics! Ideally, you would counterbalance the order in which participants take part in the different conditions. Note that participants should be randomly assigned to the order. For example, if using a within-subjects design, Max should have half of the sample rate the red-haired person first and the brown-haired person second, and vice versa for the other half of the sample.
Reducing the Influence of Extraneous Variables
Unsystematic variation of extraneous variables is present in both between- and within-subjects designs. However, for the most part, the unsystematic variation is reduced in within-subjects designs because we have the same people participate in both conditions (participant variables like age, IQ, personality are held constant). So this reduces the variability due to extraneous variables (and the chance that they might become confounds).
Another way to hold these participant variables constant is to do something called matching. In this case, you pair up participants by the extraneous variables you are concerned about, and then randomly assign one person from each pair to either the experimental or control group using a between-subjects design. For example, people’s pre-existing anxiety levels might influence how well they respond to an intervention to reduce test anxiety. You might measure test anxiety in all participants prior to randomly assigning them to an intervention or control group. Then, you would match them in pairs according to their test anxiety scores and randomly assign each participant from within each pair to one of the two conditions.
There are also some things you can do, regardless of whether you have a within- or between-subjects design, to reduce the effect of extraneous variables. First, it is important to have clear scoring criteria. We should know when a response is correct or incorrect, how to distinguish responses, and where a response begins and ends. This is easier in some situations than others. Consider, if you want to measure children’s aggressive behaviours in the playground, how would you score behaviours? What behaviours would you describe as aggressive: nudging, yelling, pushing, hitting, or kicking? You would need to develop some very clear scoring criteria so that the behaviours could be quantified and recorded. You might want to video the children playing so that multiple researchers (raters) can watch the recordings and code the responses. You could then look for agreement amongst the different raters. Second, we can use a sensitive dependent variable. Think back to levels of measurement. For example, if you ask people “how much do you like raw oysters on a scale from 1 – 10?” this is more sensitive than asking “do you like raw oysters: yes or no?” With a more sensitive measure, we can get a range of responses and detect smaller changes across levels of the independent variable. Third, we can address reliability of behaviours: on any given occasion, different extraneous variables might influence behaviour. We may have to test several times. For example, in Max’s study to asses perceived friendliness of red- and brown-haired people, features of the target faces might elicit idiosyncratic preferences for different participants. Max might want to consider presenting multiple different faces, with brown or red hair, for participants to rate.
If we are using questionnaires or scales, we need to maximize reliability of these measures too. Instructions should be clear, and we should use items that are not going to elicit idiosyncratic responses. Multiple items should be used to assess the same construct; and items should be worded carefully to be unambiguous (e.g., no double-barrelled items).
Practice trials can be help for some tasks, too. Finally, we should aim for consistency in the experimental procedures. This can be achieved by some of the following: (a) having a detailed experimental protocol (e.g., typed-out instructions that are clear, with no jargon, and the same every time [no ad libbing!]); (b) using a double-blind procedure (neither the participant nor the experimenter interacting with the participant knows what condition the participant is in); (c) automatising the experiment (e.g., using a computerized task if possible); (d) ensuring that any confederates are blind to the testing condition; (e) testing participants in groups so that they all get the same instructions (but beware if behaviour might change in a group setting); and (f) pilot testing the instructions to ensure that they are clear.
Connection to Statistics
Why does all this matter? Why should we try to maximize the effect of the independent variable on the dependent variable, while minimizing confounds and the influence of extraneous variables? Here is a really cool thing: statistical tests look at the variation in scores on the dependent variable, and compare how much variation in the dependent variable is systematic versus how much is unsystematic. It goes something like this:
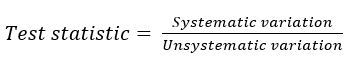
If you have confounds, the variation due to the independent variable and the variation due to the confounds are lumped together (because they are both systematic) so you cannot tell them apart! In that case, internal validity is compromised, and you will not know what caused the changes in the dependent variable! However, if you can rule out potential confounds—by being very careful in the design of your study—you are now left with just variation due to the manipulation of the independent variable and any unsystematic variation (variation due to extraneous variables).
Statistical tests compare how much variation in the dependent variable is systematic versus how much is unsystematic. You should be aiming to get a large amount of systematic variation (due to the manipulation of the independent variable)—i.e., the radio signal—relative to the amount of unsystematic variation—the static. This will allow you to obtain a large value for the test statistic and hence detect the experimental effect.
External Validity
Finally, as noted earlier in this chapter, external validity is the degree to which the results accurately generalize to other individuals and situations. A special type of external validity is ecological validity, which is the extent to which research can be generalized to natural situations. For example, will the effects of red or brown hair on perceived friendliness extend to real world settings?
It is important to note that there is often a trade-off between internal validity and external validity. We can increase internal validity through greater control, but this produces a more unnatural situation and, therefore, it lowers external validity! Generally, lab experiments have more internal validity, but field experiments have greater external validity. For some kinds of research (e.g., fundamental research to understand basic perceptual processes), you need lots of control, so you need to do this in the lab. For other kinds of research, it might be more important to focus on external validity. For example, I study emotion regulation. Lots of research either has people come into the lab, where we ask them to regulate their emotions in different ways and observe the effects on their behaviour, or we give them questionnaires where they respond by saying how they would regulate their emotions. None of this really matters if, in the former case, the strategies we ask them to use in the lab are not the ones they would use in the real world anyway and, in the latter case, if they do not do what they say they would do!
Given that external validity is a limitation in a lot of psychological studies, researchers have to be very careful how they write their conclusions to ensure that they do not extend beyond the participants and settings tested in the study.
