2 The Research Process
Let’s begin by considering an overview of the research process, shown in the figure below:
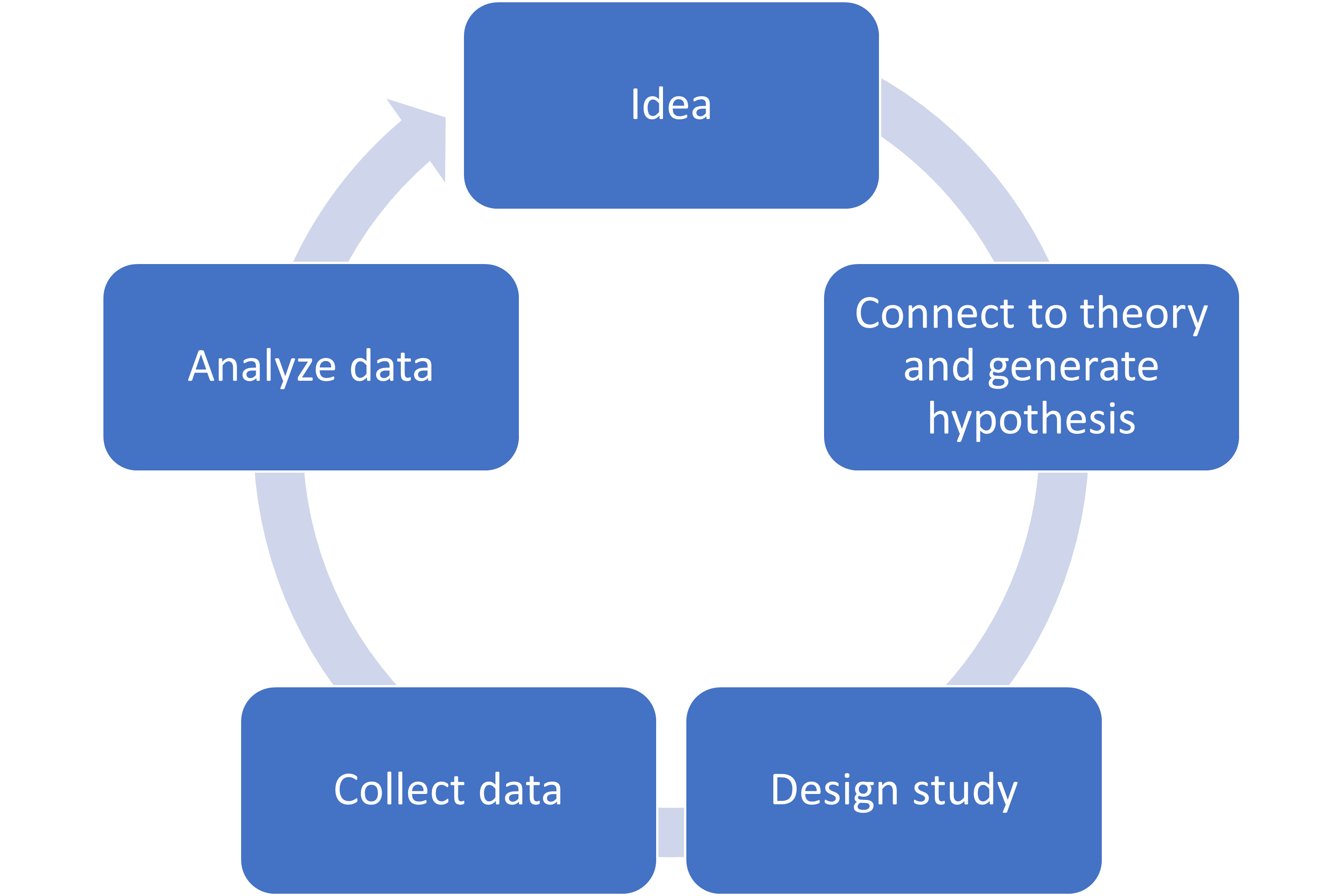
Generating the Hypothesis
Research usually starts with some research ideas and an observation. Where do those ideas come from? We might get an idea from so-called “common-sense.” (Is it true that birds of a feather flock together? Do opposites attract?) We also might get an idea from observations in our daily lives. (Max used an observation from daily life when they wondered if red-heads tended to attract a lot of friends.) However, more typically, theories and past research drive future research. Or, sometimes, research questions come from practical problems that we want to solve. (How can we reduce student stress?)
We then collect data to see whether our expectations are correct. To do this, we need to identify and define our variables. Variables are anything that can be measured, and they can differ across people (assuming we are doing research with humans), or contexts, or time.
After we have selected our general research question, we generate a hypothesis. A hypothesis is usually derived from a theory, which is a general principle or set of principles that explains known findings about a particular topic. Note: a theory is not the same as a guess or a hunch. In everyday life when people say things like “I have a theory about …” (e.g., “presidents of big corporations are all narcissistic!”) they usually mean they have a guess about something. It may be based on some observations, but there is not a full set of principles that explain a body of data, which we need for something to be called a theory. A theory allows us to generate predictions about the results of future studies. A hypothesis or prediction (note that sometimes people distinguish between these terms, but for our purposes we can use them interchangeably) is the expectation of what will happen in the context of a particular study. It is different from a research question. For example, when Max asks: “Do redheads appear more friendly than other people?” that is a research question. To make it into a hypothesis, it should be a statement, specifically in terms of the expected outcomes in the study: “I expect that redheads will receive higher ratings of friendliness than people with brown hair.”
Note that we cannot prove a hypothesis to be correct. The data we obtained might fit the hypothesis, but it is possible that the hypothesis was incorrect and that it was just a coincidence that the data fit the hypothesis. Therefore, we say that a hypothesis or prediction is supported, but not proved.
A final note about hypotheses and theories: hypotheses and theories should be falsifiable. Falsification is the act of disproving a theory or hypothesis. Many aspects of Freud’s theories about the structure of personality were not falsifiable.Let’s consider an example. A self-described psychic comes into the lab to be tested, but they are unable to demonstrate their powers. The person explains it away by saying: “Well, it’s just because you don’t believe.” Then if a believer is present, and the person still cannot demonstrate their powers, they might say: “It’s because there is a strange energy in this room that is counteracting my powers.” These excuses make the hypothesis unfalsifiable.
Designing the Study
When we design our study, there are various important considerations. What variables will we use, and how will we measure them? How will we address issues of reliability and validity? Will we use a correlational or experimental design?
Identifying the Variables
As we design our study, we need to think about our variables. In an experiment, we have independent and dependent variables. In Max’s study of people’s ratings of friendliness of redheads versus people with other hair colours, the independent variable, the variable that is directly changed or manipulated by the experimenter, is hair colour.
An independent variable should have at least two levels. The levels are simply the different values that the independent variable takes on. For example, the people in the photos have either red hair or brown hair, so there are two levels (red or brown). The dependent variable, the variable that is measured and that we expect to change as a result of the different values of the independent variable, is friendliness.
In non-experimental contexts (in correlational designs), we are less likely to use the terms independent and dependent variables. Instead, we refer to the predictor—the variable that we think might be causing a change—and the outcome or criterion—the variable that we think might be changed. Note, I say “think” because unless we actually manipulated an independent variable (as we do in an experiment), we cannot draw conclusions about cause and effect (more on that later).
| Design | Variable | Variable |
| Correlational | Predictor | Outcome |
| Experimental | Independent variable | Dependent variable |
As we design our variables, we need to consider levels of measurement. You probably recall from previous classes that variables can be considered nominal, ordinal, interval, or ratio. Let’s have a quick refresher on what these mean.
Levels of Measurement
Nominal data means any number is simply used to assign a label to the variable (e.g., what is your major? Psychology = 1, History = 2, Geography = 3, etc.). In this case, the numbers are arbitrary. They have no mathematical properties, so the numbers do not mean anything except just to represent a category. If your variable is binary or dichotomous, there are only two categories (e.g., yes/no; pass/fail; student/non-student; dead/alive). Nominal could refer to when there are two or more than two categories (e.g., whether someone is an omnivore, vegetarian, vegan, or fruitarian).
Ordinal data indicates rank order (e.g., first, second, third fastest in a race, or in class). With ordinal data, there is no information regarding differences between scores (e.g., in a race, the first person could have finished a millisecond before the second, and the second could have finished with a 5 second gap to third—the spaces between the numbers are not the same). Also, with ordinal data, there is no “zero” rank (you cannot have a zeroth position).
If you have interval data, each score indicates an actual amount, and there are equal units separating any two adjacent scores. Zero scores is possible, but does not necessarily indicate a zero amount. For example, a score of zero on a memory test does not mean you have “no memory.” The distance between a score of one and two is same as between two and three on a memory test, in that one more word was remembered in each case (but note, this could be tricky because the words are not necessarily equivalent in terms of how easily they are remembered).
Ratio data has a true zero that actually means there is zero amount of it present (e.g., if you are counting how many years someone spent living in Kamloops, the number of friends you have, or the number of classes attended). The scores measure an actual amount, and ratio statements are possible (e.g., if Sam attended 2 classes and Amrit attended 6 classes, Amrit attended 3 times as many classes as Sam).
Finally, it is worth mentioning the difference between discrete and continuous variables, because you will hear these terms used as well. Discrete variables are things that can only be measured in whole number amounts. Usually nominal and ordinal variables are discrete, but ratio data can also be discrete (e.g., the number of friends you have). Continuous data allows for fractions (at least in theory). For example, your feelings of happiness right now on a scale from 1 to 10 could be anything from 1 to 10 (even if I require you to give a whole number for your answer, theoretically your true feelings of happiness might be somewhere around 9.5 (e.g., if the pure joy of embarking on your statistics class is tempered only slightly by the fact that it is a cloudy day).
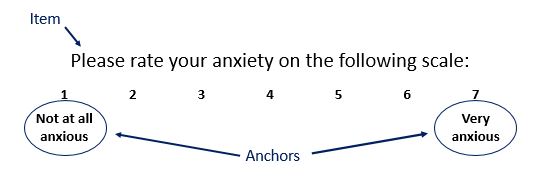
Why Do Levels of Measurement Matter?
Levels of measurement determine our ability to detect differences or change. You will have different degrees of precision or sensitivity according to the level of measurement. You will get a lot more information from an interval or ratio scale than nominal scale. Similarly, you can get much more information on a continuous variable than on a dichotomous variable. Think about asking “Are you anxious: yes or no?” which is dichotomous, versus “How anxious are you on a scale from 1 to 10?” which is a continuous variable. The former may not allow you to detect changes in anxiety from before to after an intervention, for example. Perhaps people feel very anxious before the intervention and only mildly anxious after the intervention, but at both timepoints they are going to answer “Yes” to that question! Thus, we would say that the latter item is more sensitive than the former. At the same time, simply adding more points to the scale is not always better. We could ask “How anxious are you on a scale from 1 to 100?” and your participants might find it very difficult to answer. What is the difference between 64 and 65 on this scale when rating subjective anxiety?
Levels of measurement impact what kinds of statistical tests we can use (we will learn more on this as we get into each statistical test). Note that there is often a fair bit of confusion about the difference between interval and ratio data. Note that for the purposes of choosing a statistical test, we do not need to distinguish between interval and ratio data.
Reliability and Validity
An important consideration when designing our measures is measurement error. This is the difference between the actual value we are trying to measure, and the number we use to represent that value. Let’s say you are going to treat your roommates to a home-baked chocolate cake. You are weighing some flour. You put flour into the bowl on your scales. The scale tells you that the weight is only 200 g. In fact, your scales are not very accurate, and you already have 300 g of flour in the bowl. However, you do not know this, so you add more flour. Sadly, your cake will be very dry and dense. There was a lot of measurement error here! To keep measurement error to a minimum, we need to increase validity and reliability.
Validity
There are several different types of validity. Very generally, validity refers to the extent to which an instrument measures what it set out to measure. More specifically, content validity is the extent to which the measure actually reflects the variable of interest (e.g., if I have developed a test of memory, does it measure memory alone, and not something else, like attention or fatigue; if I have a scale assessing clinical depression, does it assess only depression and not anxiety). External validity is the extent to which the results generalize to other situations or settings (generalizability). Ecological validity is a special type of external validity which relates to the extent to which research can be generalized to common real-world behaviours and natural situations. So, if you were studying the effects of study time on memory for a list of abstract nouns (like justice, hate, self-esteem, curiosity) you might ask yourself: Do we ever do this in everyday life? Would memory operate similarly if someone is trying to memorize a shopping list?
Later we shall talk about internal validity, which is a special type of validity related to the relationship between variables.
Reliability
Reliability is the ability of the measure to produce the same results under the same conditions. Test–retest reliability refers to whether the measurements are consistent. Is the same score produced each time a particular behaviour is measured? Are the scores stable over repeated testings? For reliability, I would expect that if you rate a particular photo as attractive now, you will feel the same way about it 10 minutes from now, and tomorrow, and next week. Otherwise, it would be a pretty unreliable measurement that could have big effects on your results.
Why should we care about reliability? Reliability is an important consideration in our research design because often we want to see a change in scores as a result of our manipulation of the independent variable. We need to know that any change in scores is because of the manipulation, and not because the test is unreliable. Perfect reliability is very hard to achieve when measuring psychological variables. However, it is important to increase reliability as much as we can, as it affects our ability to detect change or differences, as you will see when we start to learn about statistical tests.
Research Design
Do you remember the difference between correlational and experimental research? Let’s have a brief review here. The main differences are that with correlational research, we simply measure variables. In correlational research, the variables are measured to determine if there is an association; no variables are manipulated. Of course, this yields two big problems. The first problem is the direction of cause and effect problem. We do not know which variable caused which. The second problem is the third variable problem. Perhaps the variables are not causally related at all, and some uncontrolled third variable may be responsible for the observed association between the variables. (More on these issues in Chapter 10, Correlational Design.)
In experimental research, one or more variable(s) is systematically manipulated to see their effect (alone or in combination) on an outcome variable. Researchers vary the presence or strength of an independent variable and determine whether those variations have an impact on the behaviour or mental process in question (the dependent variable). The goal is to determine cause and effect. Does a certain variable influence a particular behaviour. Does watching TV violence affect aggression levels in children? Does mood affect memory performance? Experimental research allows us to determine cause and effect. Note that experimental research can take place in the laboratory or outside of the lab (in the “field”).
So why would we ever use correlational research? There are a few situations when it is very useful. For example, sometimes it is unethical or impossible to manipulate a variable of interest (e.g., if you want to study the effects of maternal smoking on infant health outcomes; or when the focus of the research is on participant characteristics such as age or personality, which cannot be manipulated). Sometimes, the goal of the research is to describe variables and their potential relationships, which is particularly important in the early stages of research. Or, you may wish to predict future behaviour, such as when you are studying the relation between a predictor variable and some criterion (e.g., you might measure beliefs about intelligence at the beginning of university and look at how this predicts academic performance). Finally, correlational research is easier to conduct outside of the lab than experiments, so there is the potential for greater external and ecological validity. (And with better external validity, you may be better able to predict behaviours.)
But we must consider the direction of cause and effect problem. Consider this example: on the CBC there was a news item about research showing that people with dementia were more likely to be living close to highways. Did the dementia cause the people to make such choices, or does living near a highway somehow cause dementia? We cannot conclude from the (correlational) research that living near the highway caused dementia. Also, remember the third variable problem. Perhaps socioeconomic status is a causal variable both in where people live (houses closer to the highway might be cheaper) and in increasing the risk of dementia. Socioeconomic status would therefore be a third variable, and dementia and living location would not be causally related at all.
I hope by now that you would agree that correlational designs do not allow us to infer cause and effect. To infer cause and effect, we need to rule out all other explanations of the potential cause-effect relationship. We need to show that the effect is present when the cause is present and that when the cause is absent, the effect is also absent. The way to do this is to compare two controlled situations: in one condition, the cause is present, and in the other condition, the cause is absent. To do this, we can run an experiment.
We shall have a closer look at research design for correlational studies later in the book (see Chapter 10, Correlational Design). For now, we are going to focus on experiments.
